03:00
3 - What makes a model?
Introduction to Machine Learning in R with tidymodels
Your turn

How do you fit a linear model in R?
How many different ways can you think of?
lmfor linear modelglmnetfor regularized regressionkerasfor regression using TensorFlowstanfor Bayesian regressionsparkfor large data setsbruleefor regression using torch
To specify a model ![]()

- Choose a model type
- Specify an engine
- Set the mode

To specify a model ![]()
To specify a model ![]()
- Choose a model type
- Specify an engine
- Set the mode
To specify a model ![]()
To specify a model ![]()
To specify a model ![]()
- Choose a model type
- Specify an engine
- Set the mode
To specify a model ![]()
To specify a model ![]()
All available models are listed at https://www.tidymodels.org/find/parsnip/
To specify a model ![]()
- Choose a model type
- Specify an engine
- Set the mode
Your turn
Run the tree_spec chunk in your .qmd.
Edit this code to use a logistic regression model.
All available models are listed at https://www.tidymodels.org/find/parsnip/
Extension/Challenge: Edit this code to use a different model. For example, try using a conditional inference tree as implemented in the partykit package by changing the engine - or try an entirely different model type!
05:00
Logistic regression

Logistic regression

Logistic regression

- Logit of outcome probability modeled as linear combination of predictors:
\(log(\frac{p}{1 - p}) = \beta_0 + \beta_1\cdot \text{A}\)
- Find a sigmoid line that separates the two classes
Decision trees

Decision trees

Series of splits or if/then statements based on predictors
First the tree grows until some condition is met (maximum depth, no more data)
Then the tree is pruned to reduce its complexity
Decision trees


All models are wrong, but some are useful!
Logistic regression

Decision trees

Workflows bind preprocessors and models
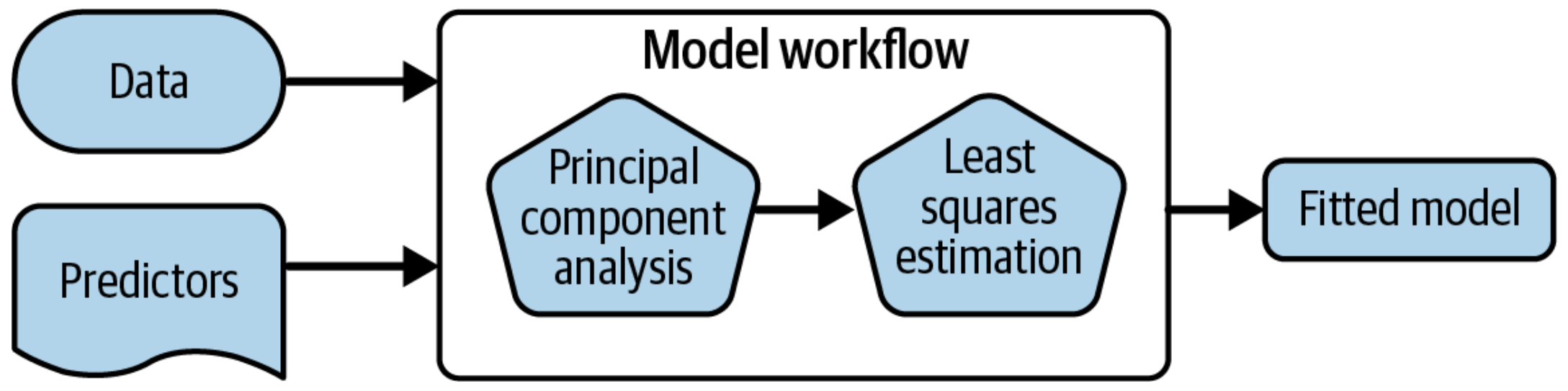
What is wrong with this?
Why a workflow()? ![]()

- Workflows handle new data better than base R tools in terms of new factor levels
- You can use other preprocessors besides formulas (more on this in Getting More Out of Feature Engineering and Tuning for Machine Learning)
- They can help organize your work when working with multiple models
- Most importantly, a workflow captures the entire modeling process:
fit()andpredict()apply to the preprocessing steps in addition to the actual model fit
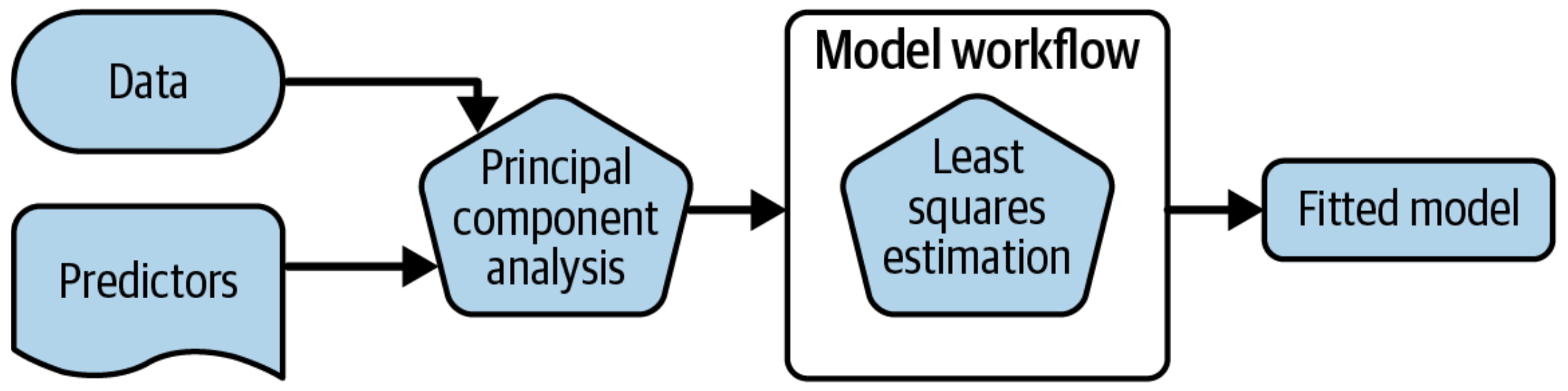
A model workflow ![]()
![]()
tree_spec <-
decision_tree() |>
set_mode("classification")
tree_spec |>
fit(forested ~ ., data = forested_train)
#> parsnip model object
#>
#> n= 8749
#>
#> node), split, n, loss, yval, (yprob)
#> * denotes terminal node
#>
#> 1) root 8749 2427 Yes (0.7225969 0.2774031)
#> 2) county=Appling,Atkinson,Bacon,Baldwin,Ben Hill,Brantley,Brooks,Bryan,Bulloch,Burke,Butts,Camden,Candler,Carroll,Charlton,Chattahoochee,Chattooga,Cherokee,Clinch,Coffee,Coweta,Crawford,Dade,Dawson,Dodge,Dougherty,Douglas,Echols,Effingham,Elbert,Emanuel,Evans,Fannin,Floyd,Gilmer,Glascock,Greene,Habersham,Hancock,Haralson,Harris,Heard,Jasper,Jeff Davis,Jefferson,Jenkins,Johnson,Jones,Lamar,Lanier,Laurens,Lee,Lincoln,Long,Lumpkin,Marion,McDuffie,Meriwether,Monroe,Montgomery,Morgan,Murray,Oconee,Oglethorpe,Paulding,Pickens,Pierce,Pike,Polk,Putnam,Quitman,Rabun,Randolph,Schley,Screven,Spalding,Stephens,Stewart,Talbot,Taliaferro,Tattnall,Taylor,Telfair,Terrell,Towns,Treutlen,Troup,Twiggs,Union,Upson,Walker,Ware,Warren,Washington,Wayne,Webster,Wheeler,White,Wilcox,Wilkes,Wilkinson 5598 1005 Yes (0.8204716 0.1795284) *
#> 3) county=Baker,Banks,Barrow,Bartow,Berrien,Bibb,Bleckley,Calhoun,Catoosa,Chatham,Clarke,Clay,Clayton,Cobb,Colquitt,Columbia,Cook,Crisp,Decatur,DeKalb,Dooly,Early,Fayette,Forsyth,Franklin,Fulton,Glynn,Gordon,Grady,Gwinnett,Hall,Hart,Henry,Houston,Irwin,Jackson,Liberty,Lowndes,Macon,Madison,McIntosh,Miller,Mitchell,Muscogee,Newton,Peach,Pulaski,Richmond,Rockdale,Seminole,Sumter,Thomas,Tift,Toombs,Turner,Walton,Whitfield,Worth 3151 1422 Yes (0.5487147 0.4512853)
#> 6) canopy_cover>=41.5 1773 603 Yes (0.6598985 0.3401015) *
#> 7) canopy_cover< 41.5 1378 559 No (0.4056604 0.5943396) *A model workflow ![]()
![]()
tree_spec <-
decision_tree() |>
set_mode("classification")
workflow() |>
add_formula(forested ~ .) |>
add_model(tree_spec) |>
fit(data = forested_train)
#> ══ Workflow [trained] ════════════════════════════════════════════════
#> Preprocessor: Formula
#> Model: decision_tree()
#>
#> ── Preprocessor ──────────────────────────────────────────────────────
#> forested ~ .
#>
#> ── Model ─────────────────────────────────────────────────────────────
#> n= 8749
#>
#> node), split, n, loss, yval, (yprob)
#> * denotes terminal node
#>
#> 1) root 8749 2427 Yes (0.7225969 0.2774031)
#> 2) county=Appling,Atkinson,Bacon,Baldwin,Ben Hill,Brantley,Brooks,Bryan,Bulloch,Burke,Butts,Camden,Candler,Carroll,Charlton,Chattahoochee,Chattooga,Cherokee,Clinch,Coffee,Coweta,Crawford,Dade,Dawson,Dodge,Dougherty,Douglas,Echols,Effingham,Elbert,Emanuel,Evans,Fannin,Floyd,Gilmer,Glascock,Greene,Habersham,Hancock,Haralson,Harris,Heard,Jasper,Jeff Davis,Jefferson,Jenkins,Johnson,Jones,Lamar,Lanier,Laurens,Lee,Lincoln,Long,Lumpkin,Marion,McDuffie,Meriwether,Monroe,Montgomery,Morgan,Murray,Oconee,Oglethorpe,Paulding,Pickens,Pierce,Pike,Polk,Putnam,Quitman,Rabun,Randolph,Schley,Screven,Spalding,Stephens,Stewart,Talbot,Taliaferro,Tattnall,Taylor,Telfair,Terrell,Towns,Treutlen,Troup,Twiggs,Union,Upson,Walker,Ware,Warren,Washington,Wayne,Webster,Wheeler,White,Wilcox,Wilkes,Wilkinson 5598 1005 Yes (0.8204716 0.1795284) *
#> 3) county=Baker,Banks,Barrow,Bartow,Berrien,Bibb,Bleckley,Calhoun,Catoosa,Chatham,Clarke,Clay,Clayton,Cobb,Colquitt,Columbia,Cook,Crisp,Decatur,DeKalb,Dooly,Early,Fayette,Forsyth,Franklin,Fulton,Glynn,Gordon,Grady,Gwinnett,Hall,Hart,Henry,Houston,Irwin,Jackson,Liberty,Lowndes,Macon,Madison,McIntosh,Miller,Mitchell,Muscogee,Newton,Peach,Pulaski,Richmond,Rockdale,Seminole,Sumter,Thomas,Tift,Toombs,Turner,Walton,Whitfield,Worth 3151 1422 Yes (0.5487147 0.4512853)
#> 6) canopy_cover>=41.5 1773 603 Yes (0.6598985 0.3401015) *
#> 7) canopy_cover< 41.5 1378 559 No (0.4056604 0.5943396) *A model workflow ![]()
![]()
tree_spec <-
decision_tree() |>
set_mode("classification")
workflow(forested ~ ., tree_spec) |>
fit(data = forested_train)
#> ══ Workflow [trained] ════════════════════════════════════════════════
#> Preprocessor: Formula
#> Model: decision_tree()
#>
#> ── Preprocessor ──────────────────────────────────────────────────────
#> forested ~ .
#>
#> ── Model ─────────────────────────────────────────────────────────────
#> n= 8749
#>
#> node), split, n, loss, yval, (yprob)
#> * denotes terminal node
#>
#> 1) root 8749 2427 Yes (0.7225969 0.2774031)
#> 2) county=Appling,Atkinson,Bacon,Baldwin,Ben Hill,Brantley,Brooks,Bryan,Bulloch,Burke,Butts,Camden,Candler,Carroll,Charlton,Chattahoochee,Chattooga,Cherokee,Clinch,Coffee,Coweta,Crawford,Dade,Dawson,Dodge,Dougherty,Douglas,Echols,Effingham,Elbert,Emanuel,Evans,Fannin,Floyd,Gilmer,Glascock,Greene,Habersham,Hancock,Haralson,Harris,Heard,Jasper,Jeff Davis,Jefferson,Jenkins,Johnson,Jones,Lamar,Lanier,Laurens,Lee,Lincoln,Long,Lumpkin,Marion,McDuffie,Meriwether,Monroe,Montgomery,Morgan,Murray,Oconee,Oglethorpe,Paulding,Pickens,Pierce,Pike,Polk,Putnam,Quitman,Rabun,Randolph,Schley,Screven,Spalding,Stephens,Stewart,Talbot,Taliaferro,Tattnall,Taylor,Telfair,Terrell,Towns,Treutlen,Troup,Twiggs,Union,Upson,Walker,Ware,Warren,Washington,Wayne,Webster,Wheeler,White,Wilcox,Wilkes,Wilkinson 5598 1005 Yes (0.8204716 0.1795284) *
#> 3) county=Baker,Banks,Barrow,Bartow,Berrien,Bibb,Bleckley,Calhoun,Catoosa,Chatham,Clarke,Clay,Clayton,Cobb,Colquitt,Columbia,Cook,Crisp,Decatur,DeKalb,Dooly,Early,Fayette,Forsyth,Franklin,Fulton,Glynn,Gordon,Grady,Gwinnett,Hall,Hart,Henry,Houston,Irwin,Jackson,Liberty,Lowndes,Macon,Madison,McIntosh,Miller,Mitchell,Muscogee,Newton,Peach,Pulaski,Richmond,Rockdale,Seminole,Sumter,Thomas,Tift,Toombs,Turner,Walton,Whitfield,Worth 3151 1422 Yes (0.5487147 0.4512853)
#> 6) canopy_cover>=41.5 1773 603 Yes (0.6598985 0.3401015) *
#> 7) canopy_cover< 41.5 1378 559 No (0.4056604 0.5943396) *Your turn
Run the tree_wflow chunk in your intro-03-classwork.qmd.
Edit this code to make a workflow with your own model of choice.
Extension/Challenge: Other than formulas, what kinds of preprocessors are supported?
05:00
Predict with your model ![]()
![]()
How do you use your new tree_fit model?
Your turn
Run:
predict(tree_fit, new_data = forested_test)
What do you notice about the structure of the result?
03:00
Your turn
Run:
augment(tree_fit, new_data = forested_test)
How does the output compare to the output from predict()?
03:00
Understand your model ![]()
![]()
How do you understand your new tree_fit model?

Understand your model ![]()
![]()
How do you understand your new tree_fit model?
You can extract_*() several components of your fitted workflow.
⚠️ Never predict() with any extracted components!
Understand your model ![]()
![]()
How do you understand your new tree_fit model?
You can use your fitted workflow for model and/or prediction explanations:
- overall variable importance, such as with the vip package
- flexible model explainers, such as with the DALEXtra package
Learn more at https://www.tmwr.org/explain.html
Your turn
Extract the model engine object from your fitted workflow and check it out.
05:00