4 - Iterative Search
Advanced tidymodels
Previously - Setup
Previously - Data Usage
Previously - Boosting Model
hotel_rec <-
recipe(avg_price_per_room ~ ., data = hotel_tr) %>%
step_YeoJohnson(lead_time) %>%
step_dummy_hash(agent, num_terms = tune("agent hash")) %>%
step_dummy_hash(company, num_terms = tune("company hash")) %>%
step_zv(all_predictors())
lgbm_spec <-
boost_tree(trees = tune(), learn_rate = tune(), min_n = tune()) %>%
set_mode("regression") %>%
set_engine("lightgbm")
lgbm_wflow <- workflow(hotel_rec, lgbm_spec)
lgbm_param <-
lgbm_wflow %>%
extract_parameter_set_dials() %>%
update(`agent hash` = num_hash(c(3, 8)),
`company hash` = num_hash(c(3, 8)))Iterative Search
Instead of pre-defining a grid of candidate points, we can model our current results to predict what the next candidate point should be.
Suppose that we are only tuning the learning rate in our boosted tree.
We could do something like:
and use this to predict and rank new learning rate candidates.
Iterative Search
A linear model probably isn’t the best choice though (more in a minute).
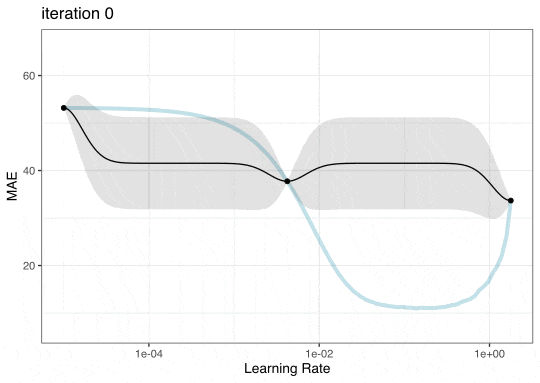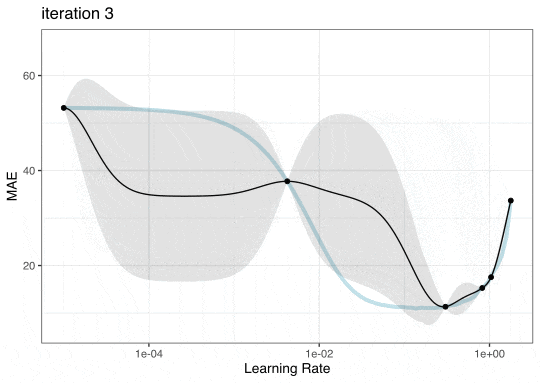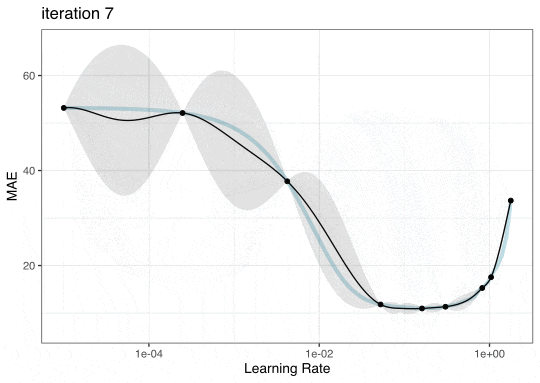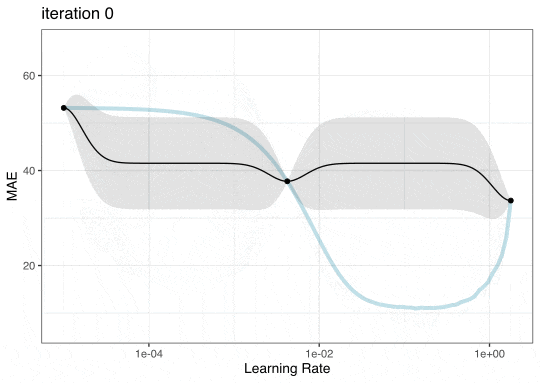
To illustrate the process, we resampled a large grid of learning rate values for our data to show what the relationship is between MAE and learning rate.
Now suppose that we used a grid of three points in the parameter range for learning rate…
A Large Grid

A Three Point Grid

Gaussian Processes and Optimization
We can make a “meta-model” with a small set of historical performance results.
Gaussian Processes (GP) models are a good choice to model performance.
- It is a Bayesian model so we are using Bayesian Optimization (BO).
- For regression, we can assume that our data are multivariate normal.
- We also define a covariance function for the variance relationship between data points. A common one is:
\[\operatorname{cov}(\boldsymbol{x}_i, \boldsymbol{x}_j) = \exp\left(-\frac{1}{2}|\boldsymbol{x}_i - \boldsymbol{x}_j|^2\right) + \sigma^2_{ij}\]
Predicting Candidates
The GP model can take candidate tuning parameter combinations as inputs and make predictions for performance (e.g. MAE)
- The mean performance
- The variance of performance
The variance is mostly driven by spatial variability (the previous equation).
The predicted variance is zero at locations of actual data points and becomes very high when far away from any observed data.
Your turn
Your GP makes predictions on two new candidate tuning parameters.
We want to minimize MAE.
Which should we choose?

03:00
GP Fit (ribbon is mean +/- 1SD)

Choosing New Candidates
This isn’t a very good fit but we can still use it.
How can we use the outputs to choose the next point to measure?
Acquisition functions take the predicted mean and variance and use them to balance:
- exploration: new candidates should explore new areas.
- exploitation: new candidates must stay near existing values.
Exploration focuses on the variance, exploitation is about the mean.
Acquisition Functions
We’ll use an acquisition function to select a new candidate.
The most popular method appears to be expected improvement (EI) above the current best results.
- Zero at existing data points.
- The expected improvement is integrated over all possible improvement (“expected” in the probability sense).
We would probably pick the point with the largest EI as the next point.
(There are other functions beyond EI.)
Expected Improvement

Iteration
Once we pick the candidate point, we measure performance for it (e.g. resampling).
Another GP is fit, EI is recomputed, and so on.
We stop when we have completed the allowed number of iterations or if we don’t see any improvement after a pre-set number of attempts.
GP Fit with four points

Expected Improvement

GP Evolution
Expected Improvement Evolution
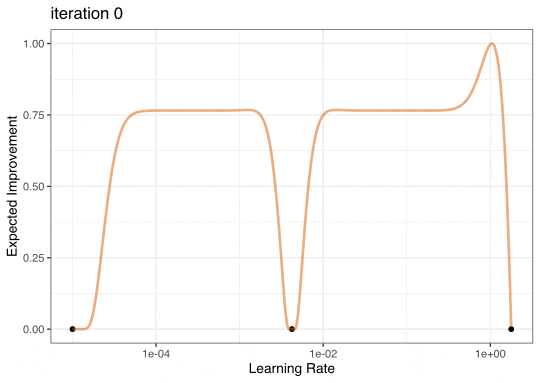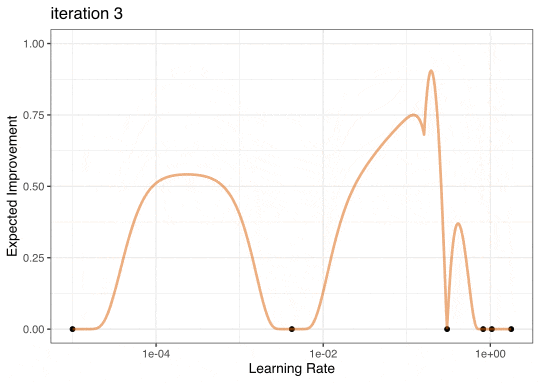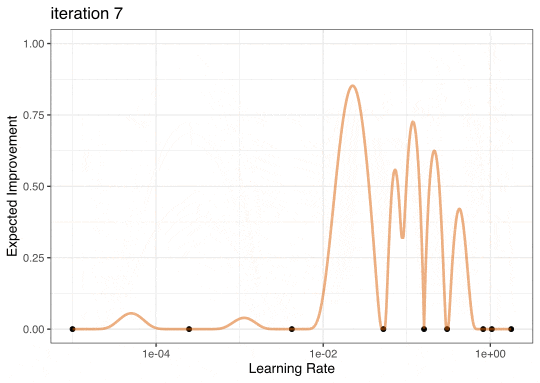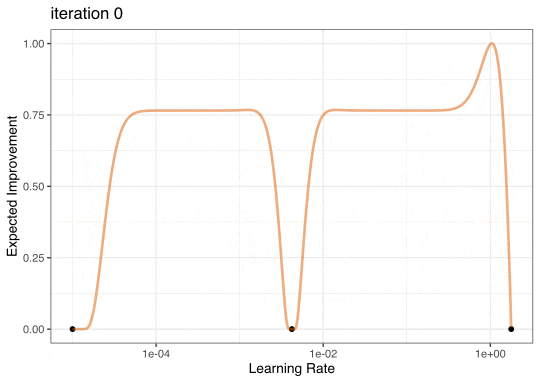
BO in tidymodels
We’ll use a function called tune_bayes() that has very similar syntax to tune_grid().
It has an additional initial argument for the initial set of performance estimates and parameter combinations for the GP model.
Initial grid points
initial can be the results of another tune_*() function or an integer (in which case tune_grid() is used under to hood to make such an initial set of results).
We’ll run the optimization more than once, so let’s make an initial grid of results to serve as the substrate for the BO.
I suggest at least the number of tuning parameters plus two as the initial grid for BO.
An Initial Grid
reg_metrics <- metric_set(mae, rsq)
set.seed(12)
init_res <-
lgbm_wflow %>%
tune_grid(
resamples = hotel_rs,
grid = nrow(lgbm_param) + 2,
param_info = lgbm_param,
metrics = reg_metrics
)
show_best(init_res, metric = "mae")
#> # A tibble: 5 × 11
#> trees min_n learn_rate `agent hash` `company hash` .metric .estimator mean n std_err .config
#> <int> <int> <dbl> <int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
#> 1 390 10 0.0139 13 62 mae standard 11.9 10 0.208 Preprocessor1_Model1
#> 2 718 31 0.00112 72 25 mae standard 29.1 10 0.325 Preprocessor4_Model1
#> 3 1236 22 0.0000261 11 17 mae standard 51.8 10 0.416 Preprocessor7_Model1
#> 4 1044 25 0.00000832 34 12 mae standard 52.8 10 0.424 Preprocessor5_Model1
#> 5 1599 7 0.0000000402 254 179 mae standard 53.2 10 0.427 Preprocessor6_Model1BO using tidymodels
set.seed(15)
lgbm_bayes_res <-
lgbm_wflow %>%
tune_bayes(
resamples = hotel_rs,
initial = init_res, # <- initial results
iter = 20,
param_info = lgbm_param,
metrics = reg_metrics
)
show_best(lgbm_bayes_res, metric = "mae")
#> # A tibble: 5 × 12
#> trees min_n learn_rate `agent hash` `company hash` .metric .estimator mean n std_err .config .iter
#> <int> <int> <dbl> <int> <int> <chr> <chr> <dbl> <int> <dbl> <chr> <int>
#> 1 1665 2 0.0593 12 59 mae standard 10.1 10 0.173 Iter13 13
#> 2 1179 2 0.0552 161 121 mae standard 10.2 10 0.147 Iter7 7
#> 3 1609 6 0.0592 186 192 mae standard 10.2 10 0.195 Iter17 17
#> 4 1352 6 0.0799 217 46 mae standard 10.3 10 0.211 Iter4 4
#> 5 1647 4 0.0819 12 240 mae standard 10.3 10 0.198 Iter20 20Plotting BO Results

Plotting BO Results

Plotting BO Results

ENHANCE

Your turn
Let’s try a different acquisition function: conf_bound(kappa).
We’ll use the objective argument to set it.
Choose your own kappa value:
- Larger values will explore the space more.
- “Large” values are usually less than one.
10:00
Notes
Stopping
tune_bayes()will return the current results.Parallel processing can still be used to more efficiently measure each candidate point.
There are a lot of other iterative methods that you can use.
The finetune package also has functions for simulated annealing search.
Finalizing the Model
Let’s say that we’ve tried a lot of different models and we like our lightgbm model the most.
What do we do now?
- Finalize the workflow by choosing the values for the tuning parameters.
- Fit the model on the entire training set.
- Verify performance using the test set.
- Document and publish the model(?)
Locking Down the Tuning Parameters
We can take the results of the Bayesian optimization and accept the best results:
best_param <- select_best(lgbm_bayes_res, metric = "mae")
final_wflow <-
lgbm_wflow %>%
finalize_workflow(best_param)
final_wflow
#> ══ Workflow ══════════════════════════════════════════════════════════
#> Preprocessor: Recipe
#> Model: boost_tree()
#>
#> ── Preprocessor ──────────────────────────────────────────────────────
#> 4 Recipe Steps
#>
#> • step_YeoJohnson()
#> • step_dummy_hash()
#> • step_dummy_hash()
#> • step_zv()
#>
#> ── Model ─────────────────────────────────────────────────────────────
#> Boosted Tree Model Specification (regression)
#>
#> Main Arguments:
#> trees = 1665
#> min_n = 2
#> learn_rate = 0.0592557571004946
#>
#> Computational engine: lightgbmThe Final Fit
We can use individual functions:
final_fit <- final_wflow %>% fit(data = hotel_tr)
# then predict() or augment()
# then compute metricsRemember that there is also a convenience function to do all of this:
set.seed(3893)
final_res <- final_wflow %>% last_fit(hotel_split, metrics = reg_metrics)
final_res
#> # Resampling results
#> # Manual resampling
#> # A tibble: 1 × 6
#> splits id .metrics .notes .predictions .workflow
#> <list> <chr> <list> <list> <list> <list>
#> 1 <split [3749/1251]> train/test split <tibble [2 × 4]> <tibble [0 × 3]> <tibble [1,251 × 4]> <workflow>Test Set Results
Test set performance:
