augment(taxi_fit, new_data = taxi_train) %>%
relocate(tip, .pred_class, .pred_yes, .pred_no)
#> # A tibble: 7,045 × 10
#> tip .pred_class .pred_yes .pred_no distance company local dow month hour
#> <fct> <fct> <dbl> <dbl> <dbl> <fct> <fct> <fct> <fct> <int>
#> 1 no no 0.0625 0.937 5.39 Flash … no Sat Mar 12
#> 2 no yes 0.924 0.0758 18.4 Sun Ta… no Sat Apr 6
#> 3 no no 0.391 0.609 5.8 other no Tue Jan 10
#> 4 no no 0.112 0.888 6.85 Flash … no Fri Apr 8
#> 5 no no 0.129 0.871 9.5 City S… no Wed Jan 7
#> 6 no no 0.326 0.674 12 other no Fri Apr 11
#> 7 no no 0.0917 0.908 8.9 Taxi A… no Mon Feb 14
#> 8 no yes 0.902 0.0980 1.38 other no Fri Apr 16
#> 9 no no 0.0917 0.908 9.12 Flash … no Wed Apr 9
#> 10 no yes 0.933 0.0668 2.28 City S… no Thu Apr 16
#> # ℹ 7,035 more rows4 - Evaluating models
Machine learning with tidymodels
Confusion matrix ![]()

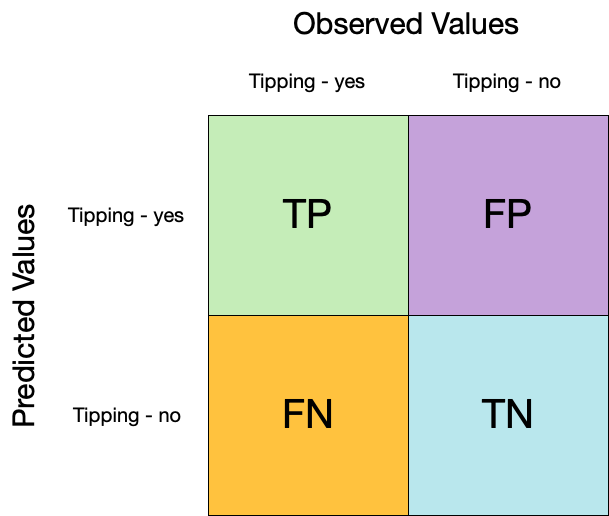
Confusion matrix ![]()
Confusion matrix ![]()

Metrics for model performance ![]()
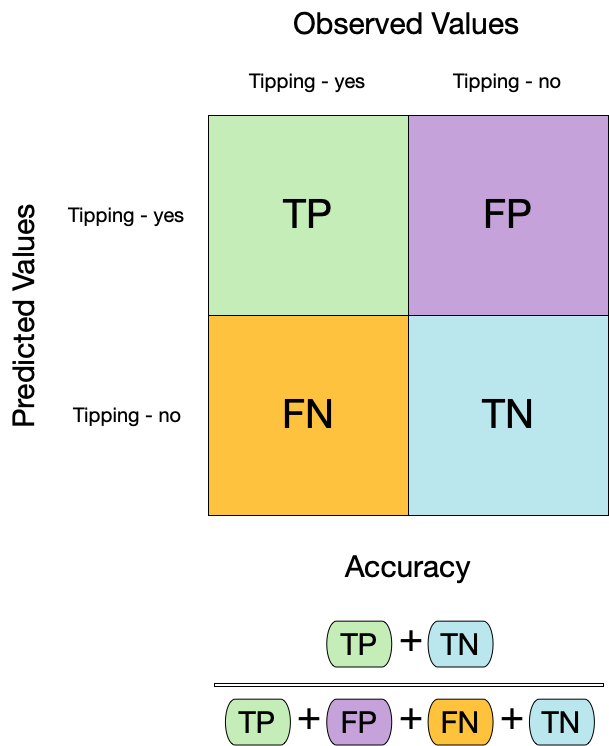
Dangers of accuracy ![]()
We need to be careful of using accuracy() since it can give “good” performance by only predicting one way with imbalanced data
Metrics for model performance ![]()
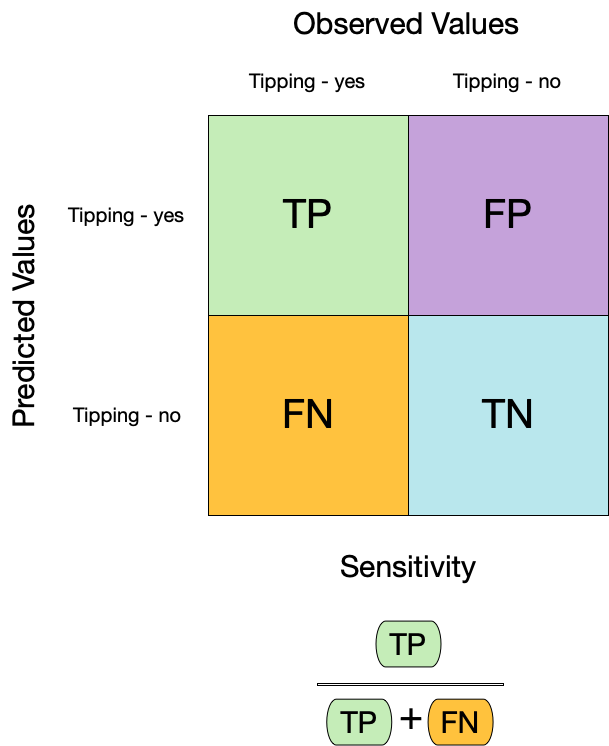
Metrics for model performance ![]()
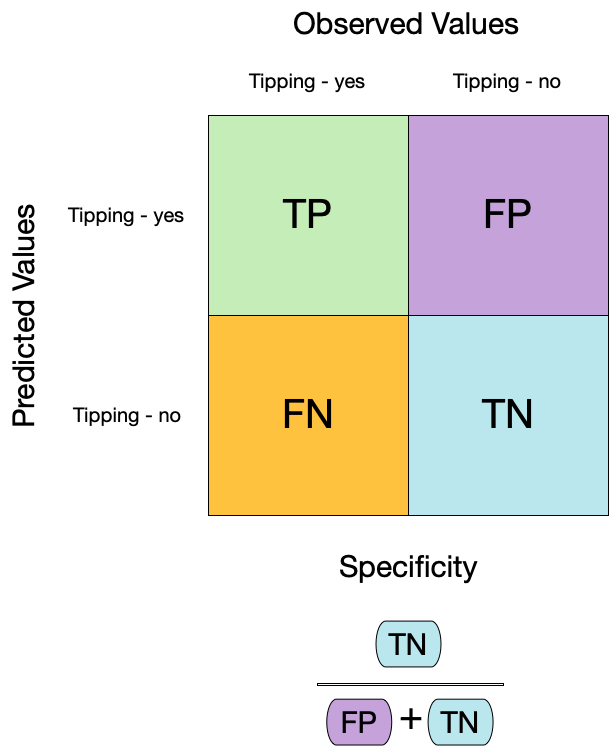
Metrics for model performance ![]()
We can use metric_set() to combine multiple calculations into one
taxi_metrics <- metric_set(accuracy, specificity, sensitivity)
augment(taxi_fit, new_data = taxi_train) %>%
taxi_metrics(truth = tip, estimate = .pred_class)
#> # A tibble: 3 × 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
#> 1 accuracy binary 0.858
#> 2 specificity binary 0.681
#> 3 sensitivity binary 0.932Metrics for model performance ![]()
taxi_metrics <- metric_set(accuracy, specificity, sensitivity)
augment(taxi_fit, new_data = taxi_train) %>%
group_by(local) %>%
taxi_metrics(truth = tip, estimate = .pred_class)
#> # A tibble: 6 × 4
#> local .metric .estimator .estimate
#> <fct> <chr> <chr> <dbl>
#> 1 yes accuracy binary 0.840
#> 2 no accuracy binary 0.862
#> 3 yes specificity binary 0.346
#> 4 no specificity binary 0.719
#> 5 yes sensitivity binary 0.969
#> 6 no sensitivity binary 0.925Varying the threshold

ROC curves ![]()
# Assumes _first_ factor level is event; there are options to change that
augment(taxi_fit, new_data = taxi_train) %>%
roc_curve(truth = tip, .pred_yes) %>%
slice(1, 20, 50)
#> # A tibble: 3 × 3
#> .threshold specificity sensitivity
#> <dbl> <dbl> <dbl>
#> 1 -Inf 0 1
#> 2 0.25 0.486 0.972
#> 3 0.6 0.705 0.920
augment(taxi_fit, new_data = taxi_train) %>%
roc_auc(truth = tip, .pred_yes)
#> # A tibble: 1 × 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
#> 1 roc_auc binary 0.868ROC curve plot ![]()

Your turn

Compute and plot an ROC curve for your current model.
What data are being used for this ROC curve plot?
05:00
Dangers of overfitting ⚠️

Dangers of overfitting ⚠️

Dangers of overfitting ⚠️ ![]()
taxi_fit %>%
augment(taxi_train)
#> # A tibble: 7,045 × 10
#> tip distance company local dow month hour .pred_class .pred_yes .pred_no
#> <fct> <dbl> <fct> <fct> <fct> <fct> <int> <fct> <dbl> <dbl>
#> 1 no 5.39 Flash … no Sat Mar 12 no 0.0625 0.937
#> 2 no 18.4 Sun Ta… no Sat Apr 6 yes 0.924 0.0758
#> 3 no 5.8 other no Tue Jan 10 no 0.391 0.609
#> 4 no 6.85 Flash … no Fri Apr 8 no 0.112 0.888
#> 5 no 9.5 City S… no Wed Jan 7 no 0.129 0.871
#> 6 no 12 other no Fri Apr 11 no 0.326 0.674
#> 7 no 8.9 Taxi A… no Mon Feb 14 no 0.0917 0.908
#> 8 no 1.38 other no Fri Apr 16 yes 0.902 0.0980
#> 9 no 9.12 Flash … no Wed Apr 9 no 0.0917 0.908
#> 10 no 2.28 City S… no Thu Apr 16 yes 0.933 0.0668
#> # ℹ 7,035 more rowsWe call this “resubstitution” or “repredicting the training set”
Dangers of overfitting ⚠️ ![]()
We call this a “resubstitution estimate”
Dangers of overfitting ⚠️ ![]()
Dangers of overfitting ⚠️ ![]()
⚠️ Remember that we’re demonstrating overfitting
⚠️ Don’t use the test set until the end of your modeling analysis
Your turn
Use augment() and and a metric function to compute a classification metric like brier_class().
Compute the metrics for both training and testing data to demonstrate overfitting!
Notice the evidence of overfitting! ⚠️
05:00
Dangers of overfitting ⚠️ ![]()
What if we want to compare more models?
And/or more model configurations?
And we want to understand if these are important differences?
Cross-validation

Cross-validation

Your turn
If we use 10 folds, what percent of the training data
- ends up in analysis
- ends up in assessment
for each fold?

03:00
Cross-validation ![]()

vfold_cv(taxi_train) # v = 10 is default
#> # 10-fold cross-validation
#> # A tibble: 10 × 2
#> splits id
#> <list> <chr>
#> 1 <split [6340/705]> Fold01
#> 2 <split [6340/705]> Fold02
#> 3 <split [6340/705]> Fold03
#> 4 <split [6340/705]> Fold04
#> 5 <split [6340/705]> Fold05
#> 6 <split [6341/704]> Fold06
#> 7 <split [6341/704]> Fold07
#> 8 <split [6341/704]> Fold08
#> 9 <split [6341/704]> Fold09
#> 10 <split [6341/704]> Fold10Cross-validation ![]()
What is in this?
Cross-validation ![]()
Cross-validation ![]()
vfold_cv(taxi_train, strata = tip)
#> # 10-fold cross-validation using stratification
#> # A tibble: 10 × 2
#> splits id
#> <list> <chr>
#> 1 <split [6340/705]> Fold01
#> 2 <split [6340/705]> Fold02
#> 3 <split [6340/705]> Fold03
#> 4 <split [6340/705]> Fold04
#> 5 <split [6340/705]> Fold05
#> 6 <split [6340/705]> Fold06
#> 7 <split [6341/704]> Fold07
#> 8 <split [6341/704]> Fold08
#> 9 <split [6341/704]> Fold09
#> 10 <split [6342/703]> Fold10Stratification often helps, with very little downside
Cross-validation ![]()
We’ll use this setup:
set.seed(123)
taxi_folds <- vfold_cv(taxi_train, v = 10, strata = tip)
taxi_folds
#> # 10-fold cross-validation using stratification
#> # A tibble: 10 × 2
#> splits id
#> <list> <chr>
#> 1 <split [6340/705]> Fold01
#> 2 <split [6340/705]> Fold02
#> 3 <split [6340/705]> Fold03
#> 4 <split [6340/705]> Fold04
#> 5 <split [6340/705]> Fold05
#> 6 <split [6340/705]> Fold06
#> 7 <split [6341/704]> Fold07
#> 8 <split [6341/704]> Fold08
#> 9 <split [6341/704]> Fold09
#> 10 <split [6342/703]> Fold10Set the seed when creating resamples
Evaluating model performance ![]()

We can reliably measure performance using only the training data 🎉
Comparing metrics ![]()
How do the metrics from resampling compare to the metrics from training and testing?
The ROC AUC previously was
- 0.87 for the training set
- 0.81 for test set
Remember that:
⚠️ the training set gives you overly optimistic metrics
⚠️ the test set is precious
Evaluating model performance ![]()
# Save the assessment set results
ctrl_taxi <- control_resamples(save_pred = TRUE)
taxi_res <- fit_resamples(taxi_wflow, taxi_folds, control = ctrl_taxi)
taxi_preds <- collect_predictions(taxi_res)
taxi_preds
#> # A tibble: 7,045 × 7
#> id .pred_yes .pred_no .row .pred_class tip .config
#> <chr> <dbl> <dbl> <int> <fct> <fct> <chr>
#> 1 Fold01 0.936 0.0638 10 yes no Preprocessor1_Model1
#> 2 Fold01 0.898 0.102 20 yes no Preprocessor1_Model1
#> 3 Fold01 0.898 0.102 47 yes no Preprocessor1_Model1
#> 4 Fold01 0.101 0.899 51 no no Preprocessor1_Model1
#> 5 Fold01 0.871 0.129 59 yes no Preprocessor1_Model1
#> 6 Fold01 0.0815 0.918 60 no no Preprocessor1_Model1
#> 7 Fold01 0.162 0.838 92 no no Preprocessor1_Model1
#> 8 Fold01 0.26 0.74 97 no no Preprocessor1_Model1
#> 9 Fold01 0.274 0.726 98 no no Preprocessor1_Model1
#> 10 Fold01 0.804 0.196 104 yes no Preprocessor1_Model1
#> # ℹ 7,035 more rowsEvaluating model performance ![]()
taxi_preds %>%
group_by(id) %>%
taxi_metrics(truth = tip, estimate = .pred_class)
#> # A tibble: 30 × 4
#> id .metric .estimator .estimate
#> <chr> <chr> <chr> <dbl>
#> 1 Fold01 accuracy binary 0.793
#> 2 Fold02 accuracy binary 0.8
#> 3 Fold03 accuracy binary 0.786
#> 4 Fold04 accuracy binary 0.804
#> 5 Fold05 accuracy binary 0.796
#> 6 Fold06 accuracy binary 0.789
#> 7 Fold07 accuracy binary 0.793
#> 8 Fold08 accuracy binary 0.808
#> 9 Fold09 accuracy binary 0.783
#> 10 Fold10 accuracy binary 0.780
#> # ℹ 20 more rowsWhere are the fitted models? ![]()
taxi_res
#> # Resampling results
#> # 10-fold cross-validation using stratification
#> # A tibble: 10 × 5
#> splits id .metrics .notes .predictions
#> <list> <chr> <list> <list> <list>
#> 1 <split [6340/705]> Fold01 <tibble [2 × 4]> <tibble [0 × 3]> <tibble>
#> 2 <split [6340/705]> Fold02 <tibble [2 × 4]> <tibble [0 × 3]> <tibble>
#> 3 <split [6340/705]> Fold03 <tibble [2 × 4]> <tibble [0 × 3]> <tibble>
#> 4 <split [6340/705]> Fold04 <tibble [2 × 4]> <tibble [0 × 3]> <tibble>
#> 5 <split [6340/705]> Fold05 <tibble [2 × 4]> <tibble [0 × 3]> <tibble>
#> 6 <split [6340/705]> Fold06 <tibble [2 × 4]> <tibble [0 × 3]> <tibble>
#> 7 <split [6341/704]> Fold07 <tibble [2 × 4]> <tibble [0 × 3]> <tibble>
#> 8 <split [6341/704]> Fold08 <tibble [2 × 4]> <tibble [0 × 3]> <tibble>
#> 9 <split [6341/704]> Fold09 <tibble [2 × 4]> <tibble [0 × 3]> <tibble>
#> 10 <split [6342/703]> Fold10 <tibble [2 × 4]> <tibble [0 × 3]> <tibble>🗑️
Bootstrapping

Bootstrapping ![]()
set.seed(3214)
bootstraps(taxi_train)
#> # Bootstrap sampling
#> # A tibble: 25 × 2
#> splits id
#> <list> <chr>
#> 1 <split [7045/2561]> Bootstrap01
#> 2 <split [7045/2577]> Bootstrap02
#> 3 <split [7045/2648]> Bootstrap03
#> 4 <split [7045/2616]> Bootstrap04
#> 5 <split [7045/2616]> Bootstrap05
#> 6 <split [7045/2599]> Bootstrap06
#> 7 <split [7045/2654]> Bootstrap07
#> 8 <split [7045/2593]> Bootstrap08
#> 9 <split [7045/2624]> Bootstrap09
#> 10 <split [7045/2615]> Bootstrap10
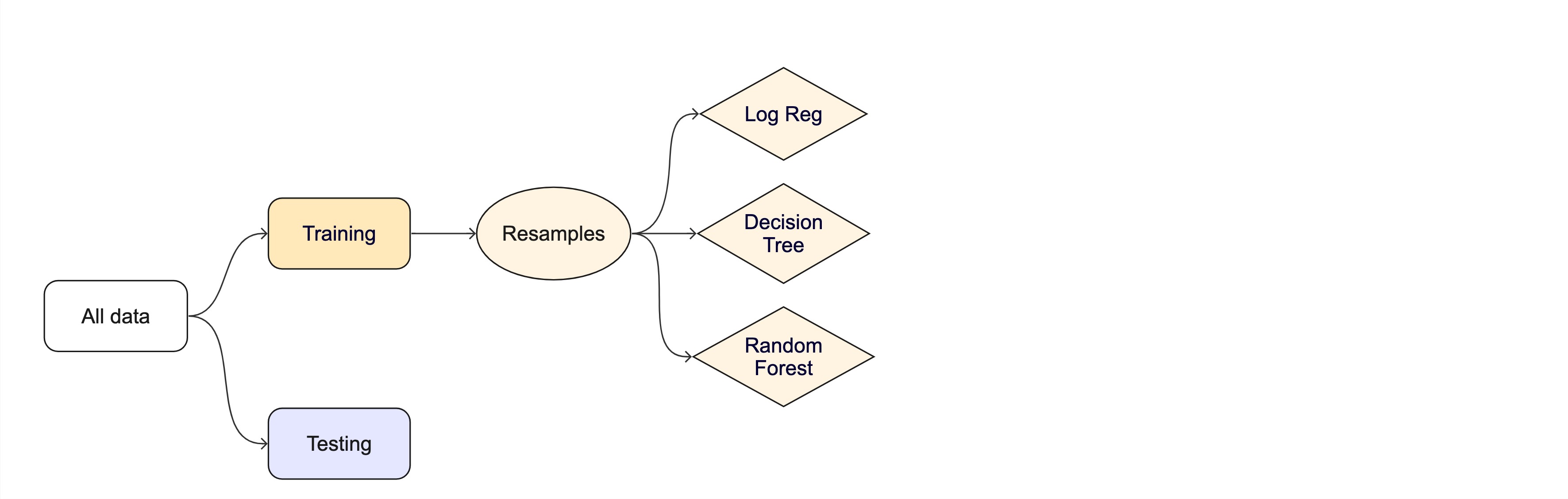
#> # ℹ 15 more rowsThe whole game - status update
Your turn
Create:
- Monte Carlo Cross-Validation sets
- validation set
(use the reference guide to find the function)
Don’t forget to set a seed when you resample!
05:00
Monte Carlo Cross-Validation ![]()
set.seed(322)
mc_cv(taxi_train, times = 10)
#> # Monte Carlo cross-validation (0.75/0.25) with 10 resamples
#> # A tibble: 10 × 2
#> splits id
#> <list> <chr>
#> 1 <split [5283/1762]> Resample01
#> 2 <split [5283/1762]> Resample02
#> 3 <split [5283/1762]> Resample03
#> 4 <split [5283/1762]> Resample04
#> 5 <split [5283/1762]> Resample05
#> 6 <split [5283/1762]> Resample06
#> 7 <split [5283/1762]> Resample07
#> 8 <split [5283/1762]> Resample08
#> 9 <split [5283/1762]> Resample09
#> 10 <split [5283/1762]> Resample10Validation set ![]()
A validation set is just another type of resample
Create a random forest model ![]()

Create a random forest model ![]()

rf_wflow <- workflow(tip ~ ., rf_spec)
rf_wflow
#> ══ Workflow ══════════════════════════════════════════════════════════
#> Preprocessor: Formula
#> Model: rand_forest()
#>
#> ── Preprocessor ──────────────────────────────────────────────────────
#> tip ~ .
#>
#> ── Model ─────────────────────────────────────────────────────────────
#> Random Forest Model Specification (classification)
#>
#> Main Arguments:
#> trees = 1000
#>
#> Computational engine: rangerYour turn
Use fit_resamples() and rf_wflow to:
- keep predictions
- compute metrics
08:00
Evaluating model performance ![]()
ctrl_taxi <- control_resamples(save_pred = TRUE)
# Random forest uses random numbers so set the seed first
set.seed(2)
rf_res <- fit_resamples(rf_wflow, taxi_folds, control = ctrl_taxi)
collect_metrics(rf_res)
#> # A tibble: 2 × 6
#> .metric .estimator mean n std_err .config
#> <chr> <chr> <dbl> <int> <dbl> <chr>
#> 1 accuracy binary 0.813 10 0.00305 Preprocessor1_Model1
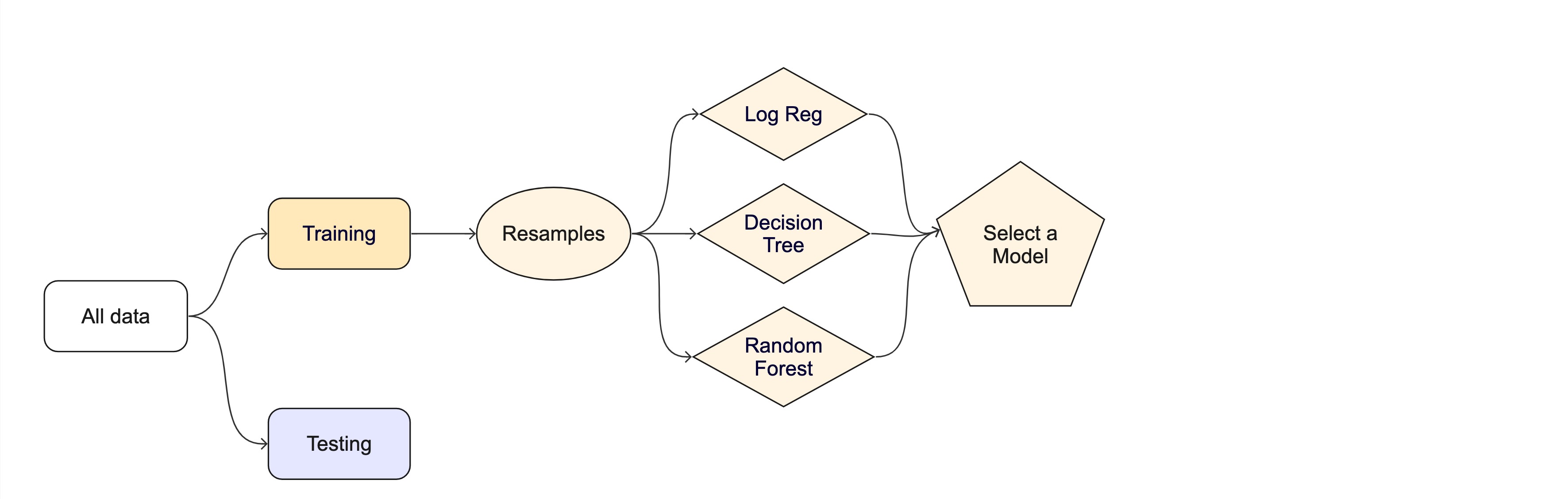
#> 2 roc_auc binary 0.832 10 0.00513 Preprocessor1_Model1How can we compare multiple model workflows at once?
Your turn
When do you think a workflow set would be useful?
03:00
The whole game - status update
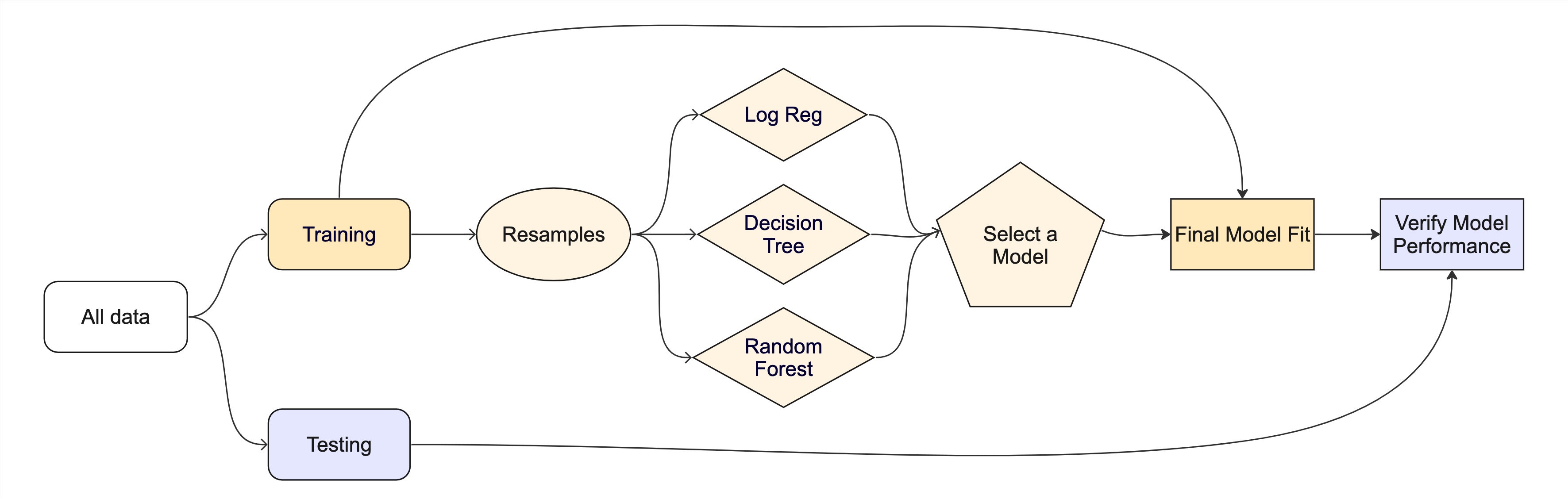
The final fit ![]()
Suppose that we are happy with our random forest model.
Let’s fit the model on the training set and verify our performance using the test set.
We’ve shown you fit() and predict() (+ augment()) but there is a shortcut:
# taxi_split has train + test info
final_fit <- last_fit(rf_wflow, taxi_split)
final_fit
#> # Resampling results
#> # Manual resampling
#> # A tibble: 1 × 6
#> splits id .metrics .notes .predictions .workflow
#> <list> <chr> <list> <list> <list> <list>
#> 1 <split [7045/1762]> train/test split <tibble> <tibble> <tibble> <workflow>What is in final_fit? ![]()
These are metrics computed with the test set
What is in final_fit? ![]()
collect_predictions(final_fit)
#> # A tibble: 1,762 × 7
#> id .pred_yes .pred_no .row .pred_class tip .config
#> <chr> <dbl> <dbl> <int> <fct> <fct> <chr>
#> 1 train/test split 0.732 0.268 10 yes no Preprocessor1_Mo…
#> 2 train/test split 0.827 0.173 29 yes yes Preprocessor1_Mo…
#> 3 train/test split 0.899 0.101 35 yes yes Preprocessor1_Mo…
#> 4 train/test split 0.914 0.0856 42 yes yes Preprocessor1_Mo…
#> 5 train/test split 0.911 0.0889 47 yes no Preprocessor1_Mo…
#> 6 train/test split 0.848 0.152 54 yes yes Preprocessor1_Mo…
#> 7 train/test split 0.580 0.420 59 yes yes Preprocessor1_Mo…
#> 8 train/test split 0.912 0.0876 62 yes yes Preprocessor1_Mo…
#> 9 train/test split 0.810 0.190 63 yes yes Preprocessor1_Mo…
#> 10 train/test split 0.960 0.0402 69 yes yes Preprocessor1_Mo…
#> # ℹ 1,752 more rowsWhat is in final_fit? ![]()
extract_workflow(final_fit)
#> ══ Workflow [trained] ════════════════════════════════════════════════
#> Preprocessor: Formula
#> Model: rand_forest()
#>
#> ── Preprocessor ──────────────────────────────────────────────────────
#> tip ~ .
#>
#> ── Model ─────────────────────────────────────────────────────────────
#> Ranger result
#>
#> Call:
#> ranger::ranger(x = maybe_data_frame(x), y = y, num.trees = ~1000, num.threads = 1, verbose = FALSE, seed = sample.int(10^5, 1), probability = TRUE)
#>
#> Type: Probability estimation
#> Number of trees: 1000
#> Sample size: 7045
#> Number of independent variables: 6
#> Mtry: 2
#> Target node size: 10
#> Variable importance mode: none
#> Splitrule: gini
#> OOB prediction error (Brier s.): 0.1373147Use this for prediction on new data, like for deploying
The whole game
Your turn
End of the day discussion!
Which model do you think you would decide to use?
What surprised you the most?
What is one thing you are looking forward to for tomorrow?
05:00